谷歌和 OpenAI 说他们能识别 AI 图片了,但这件事没那么简单
谷歌和 OpenAI 说他们能识别 AI 图片了,但这件事没那么简单
今天刷到 Google I/O 2026 的消息,有一条我盯着看了挺久。
谷歌宣布将 SynthID 识别工具引入搜索引擎和 Chrome 浏览器。以后在 Chrome 里右键点一张图,就能看到它是不是 AI 生成的。Google Lens 和"圈选即搜"也加了这个功能。
同一天,OpenAI 上线了一个验证工具,用于检测图片是否包含由其旗下产品产生的来源信号

该工具可识别 C2PA 元数据和 SynthID 水印,支持检测 ChatGPT、OpenAI API 或 Codex 生成的内容。只需上传图片,告诉你这张图有没有 OpenAI 的"来源信号"。
左脚踩右脚,这套东西,真的能用吗?
先说他们在做什么
两套系统,底层逻辑不一样,但目标一致:让 AI 生成的内容"留下痕迹"。
上面提到的两个词:SynthID 和 C2PA,这两个是什么呢?
SynthID 是 Google DeepMind 做的。2023 年 8 月首次发布,最开始只能标记图像,2024 年 10 月扩展到文本,现在又进一步嵌入了 Chrome 和搜索。
研究文档:https://deepmind.google/blog/identifying-ai-generated-images-with-synthid/

它的原理是在生成阶段就把水印"烧进去"——不是事后贴标签,而是在像素层面做不可见的修改。两个神经网络协作:一个生成图像,另一个在像素里嵌入人眼看不出来的数字签名。 对于文本,用的是一种叫伪随机函数(g-function)的方法,在 LLM 生成 token 的过程中悄悄调整概率分布,让输出带上统计指纹。
2024 年 10 月,Nature 期刊发了一篇关于 SynthID 文本水印的研究,结论是它在检测准确率上优于同类技术。谷歌同时开源了这套方案。

C2PA 是另一条线。全称 Coalition for Content Provenance and Authenticity,内容来源和真实性联盟,2021 年 2 月成立,创始成员是 Adobe、BBC、Intel、Microsoft、Arm、Truepic。现在方向委员会里有 Google、OpenAI、Meta、Sony、Amazon,总成员超过 5000 个组织。

C2PA 做的是元数据标准——给内容附上一份"出生证明",记录它是谁创建的、用什么工具、什么时间、有没有被修改过。 这份证明用密码学签名,理论上不能伪造。2022 年 1 月发布第一版规范,2026 年 1 月更新到 2.3 版。
OpenAI 的验证工具同时支持这两种:C2PA 元数据 + SynthID 水印。谷歌在 I/O 上宣布,英伟达、ElevenLabs、Kakao 也加入了 SynthID 的采用阵营。
实际效果如何呢?
本次测试是全网随机找的AI图片,主要测试的是GPT-image-2,懂得都懂,测试可能会遗漏一些极个别特殊情况,还请见谅
先看看Google识别的,通过Google Lens也是可以清楚识别出由AI生成的
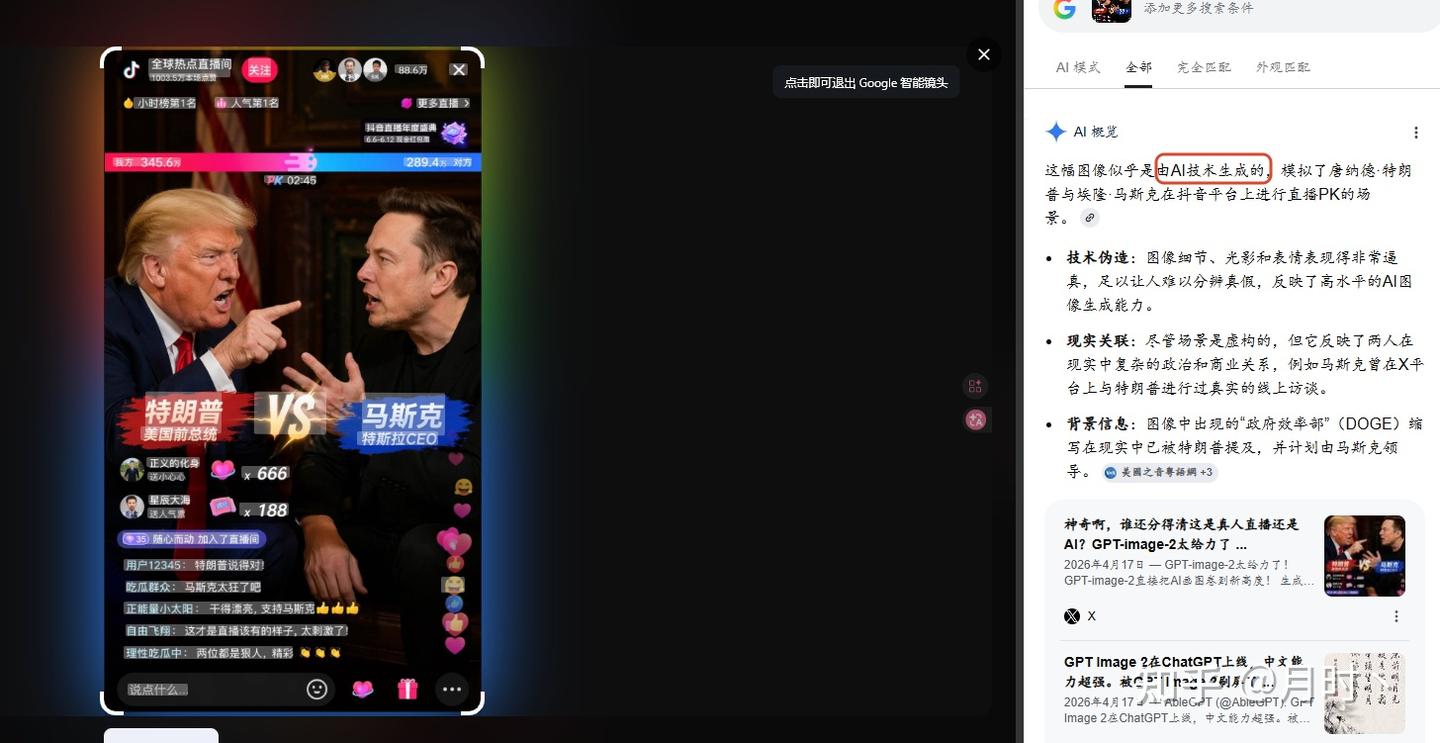
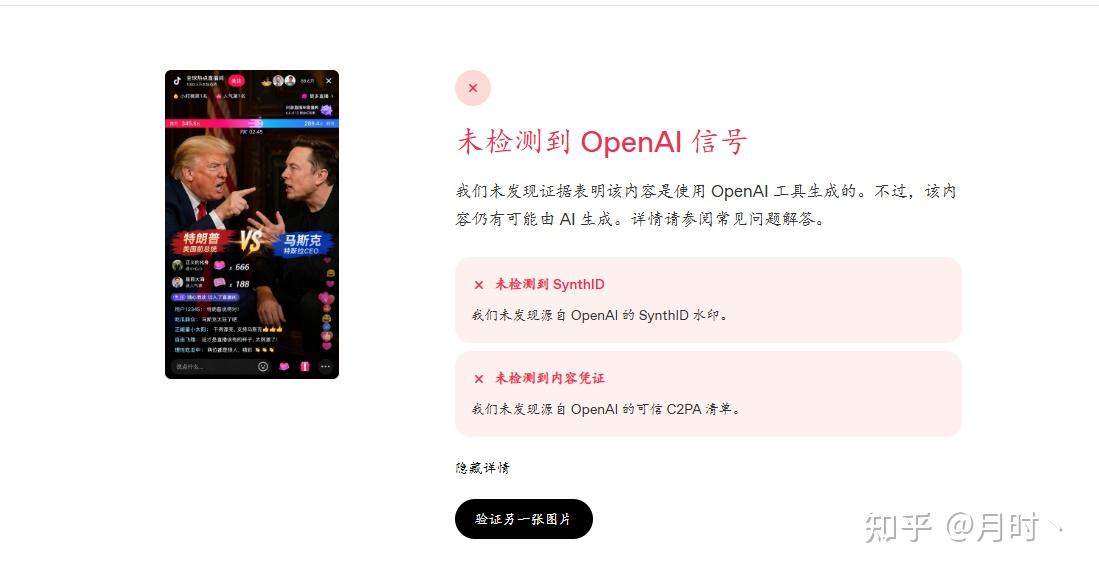
但下载下来放置到GPT验证中时,就会发现他连自己生成的都显示未检测到。我真是一脸懵,不过别急还得继续测试。
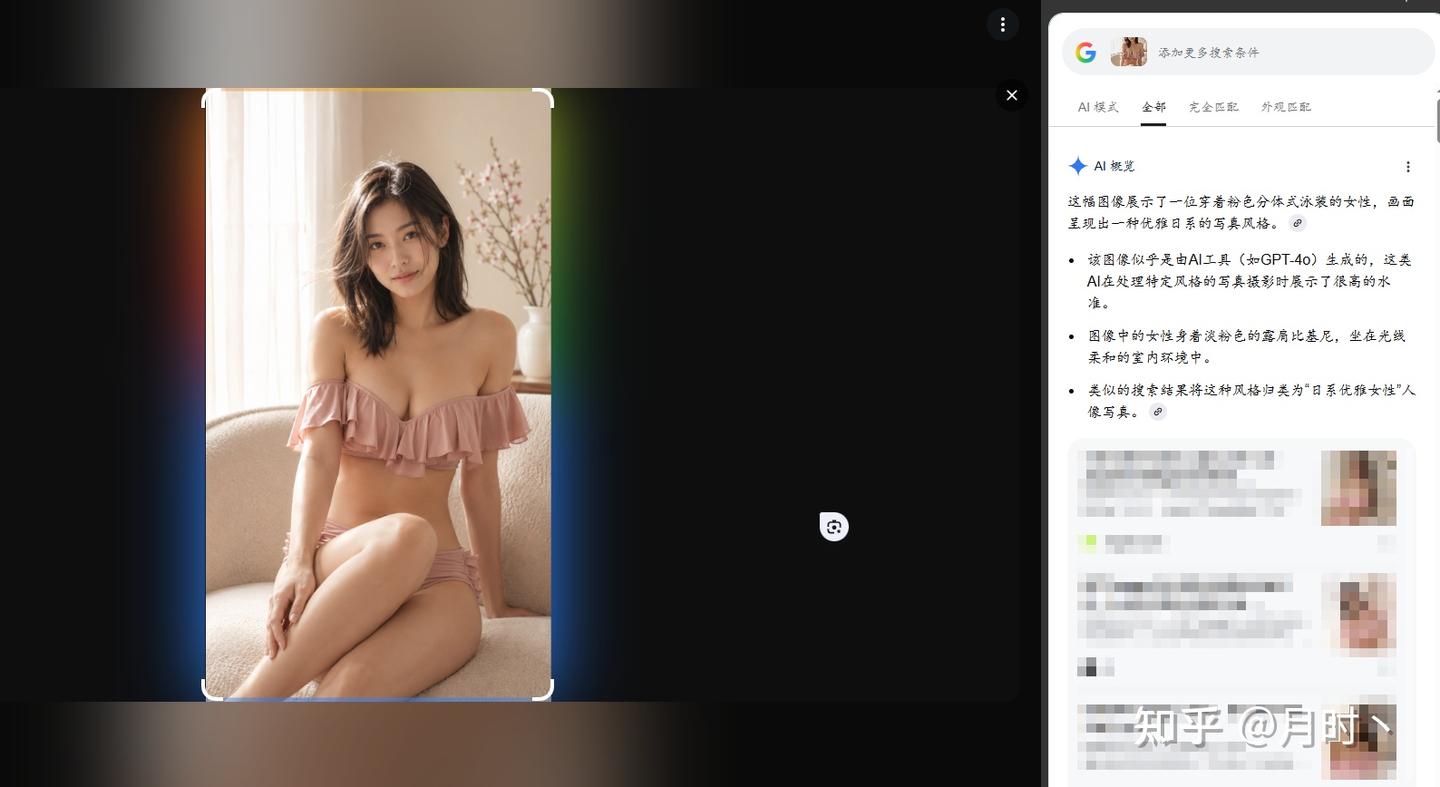
虽然上面这些人眼都是可以细微看出来的,那如果是哪些人物写真图的话呢
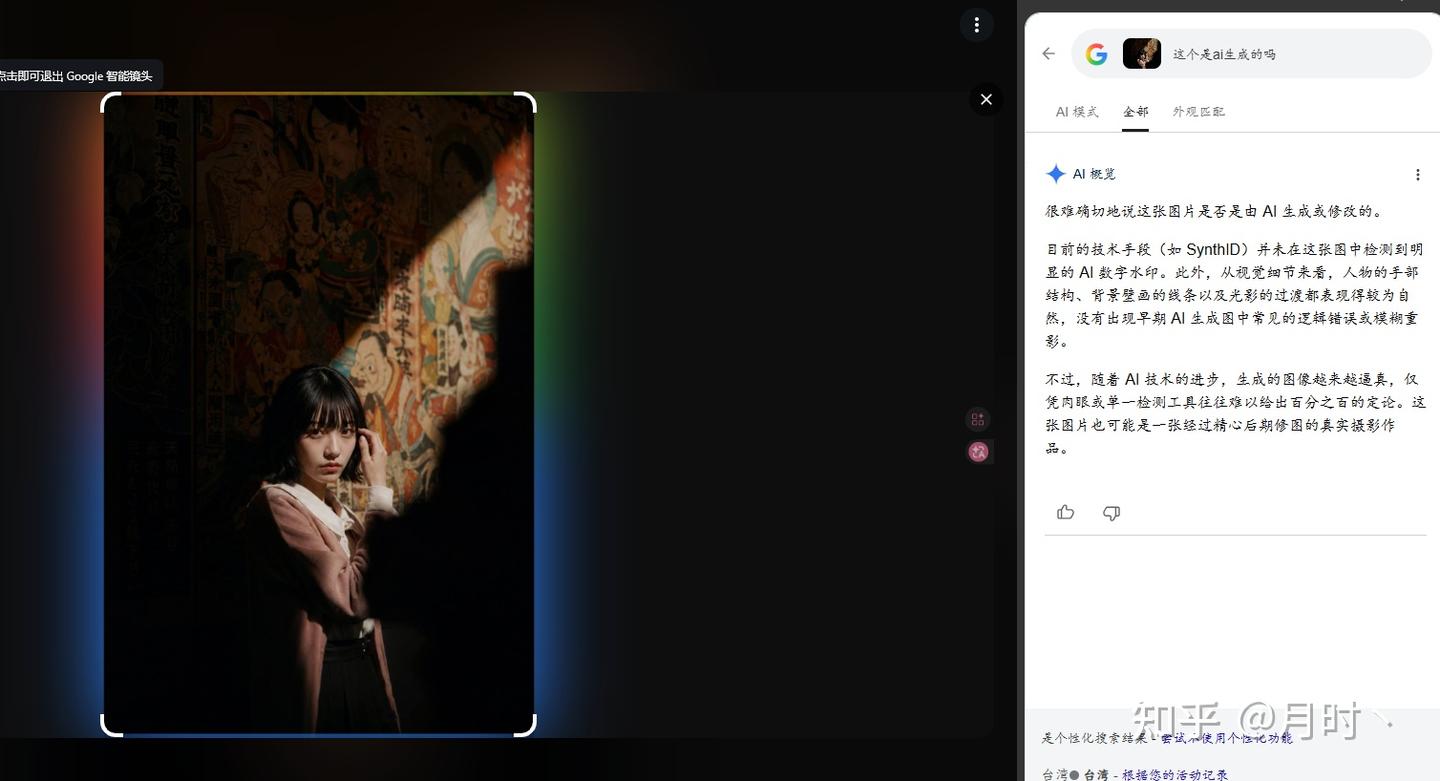

同样是支持SynthID识别的,Google却无法正常识别为AI生成,而OpenAI是可以的,上面的均是网上随机找的,不是现生成下载下来的,不排除有其他社交平台算法参与,而下面则是我在GPT上现找提示词现生成的,也没有上传过社交平台,效果如何呢?
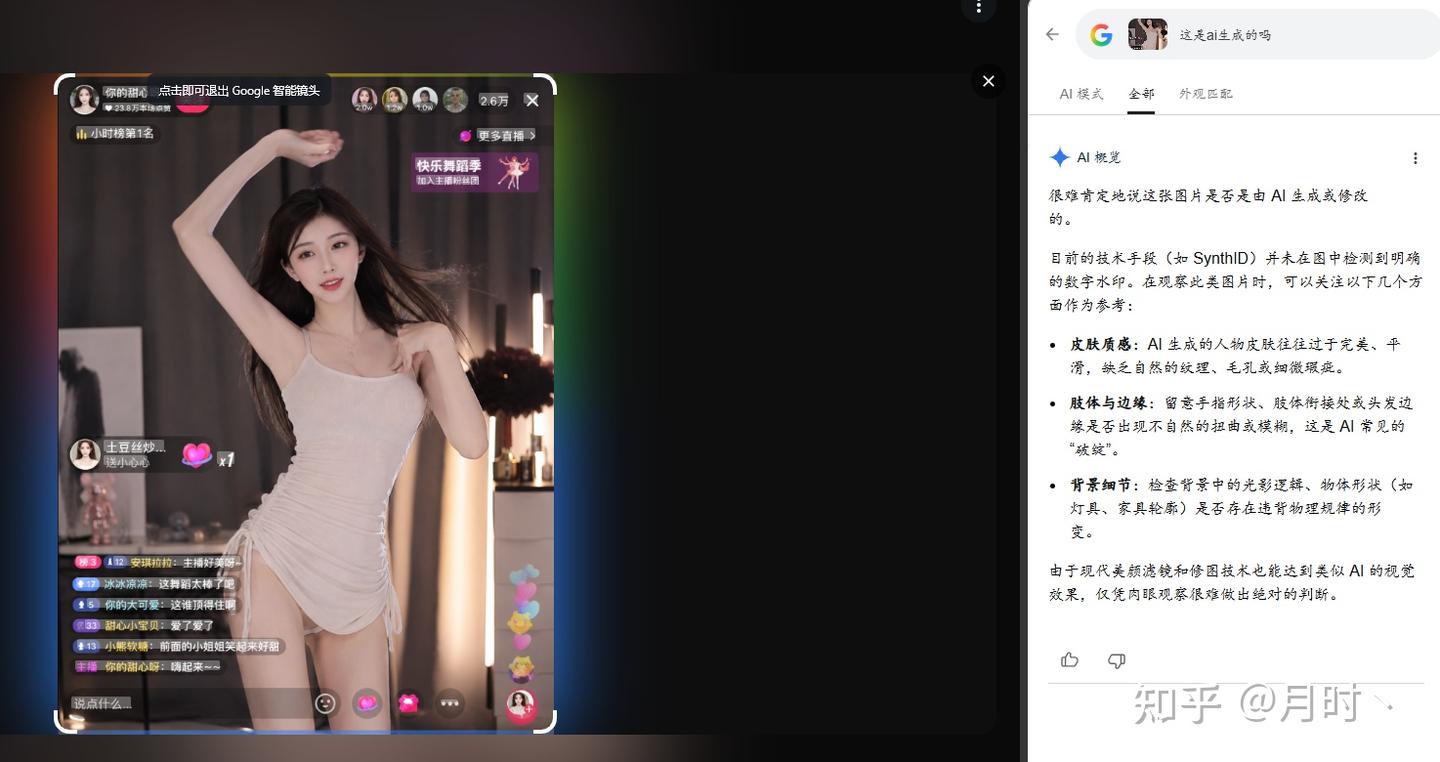
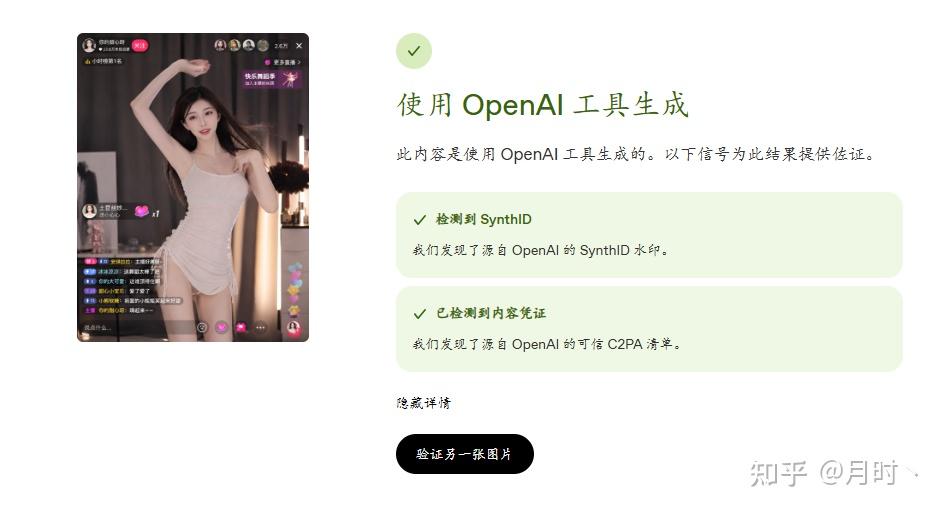
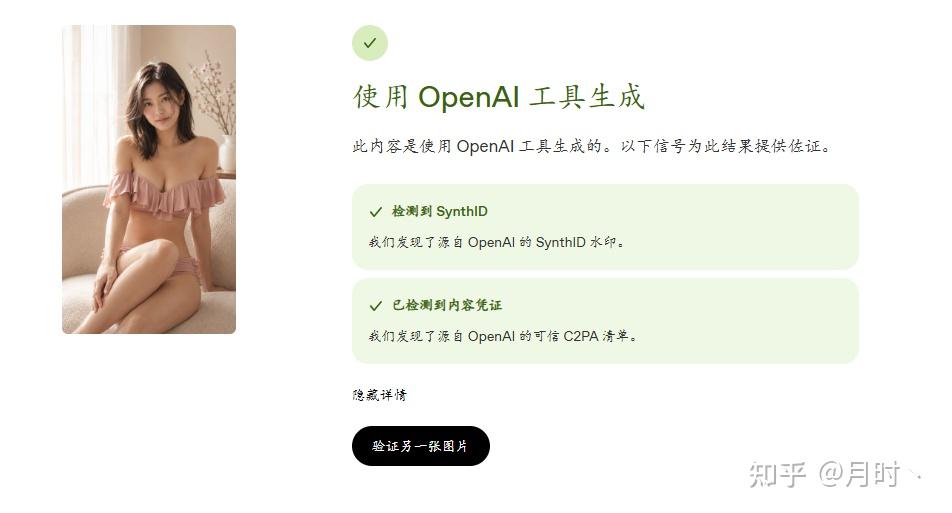
可以看出,从 GPT 生成并直接下载的原件,是可以被OpenAI成功识别出 AI 生成的,google同样是SynthID 水印却还是无法识别GPT的逼真程度。这时候就有一些小聪明就会说了,如果我不是原件呢,而是以截图方式下载下来会是怎么样的呢?
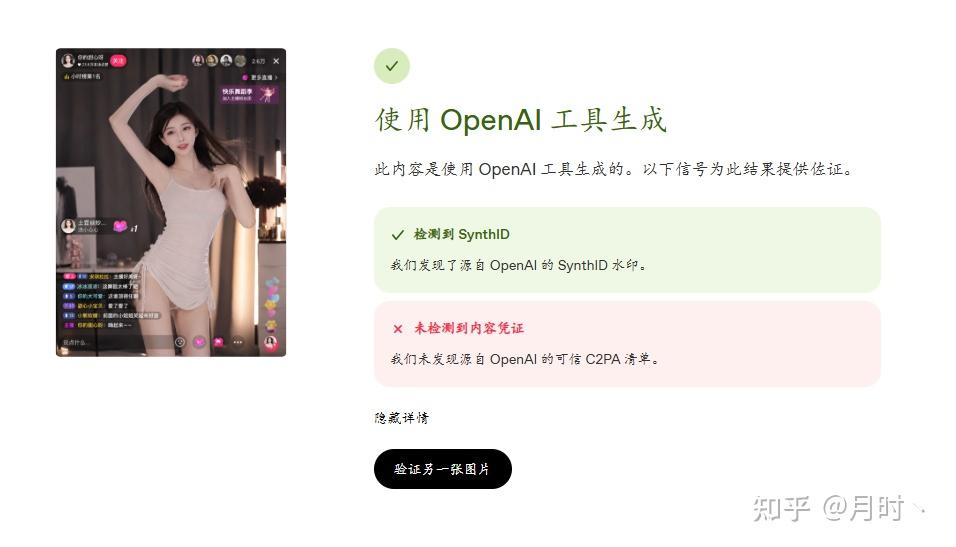

通过截图原件下载下来,然后再进行检测,虽然内容凭证是消失了,但它的SynthID 水印还是可以被OpenAI检测出来。下面我也会进行解释。不过还是会有个例无法被 OpenAI 检测出来,就像上面的第一张测试图。
这套系统的前提是什么
先说一个数字。
Axios 在 2026 年 5 月 15 日报道了 Graphite 的一项分析。Graphite 抽样 55,400 个英文网页,并使用 Pangram、GPTZero、Copyleaks 三个检测工具判断文章是否主要由 AI 生成。结果显示,AI 生成文章在 ChatGPT 发布一年后占 35.9%,两年后占 48%,此后维持在接近 50%。
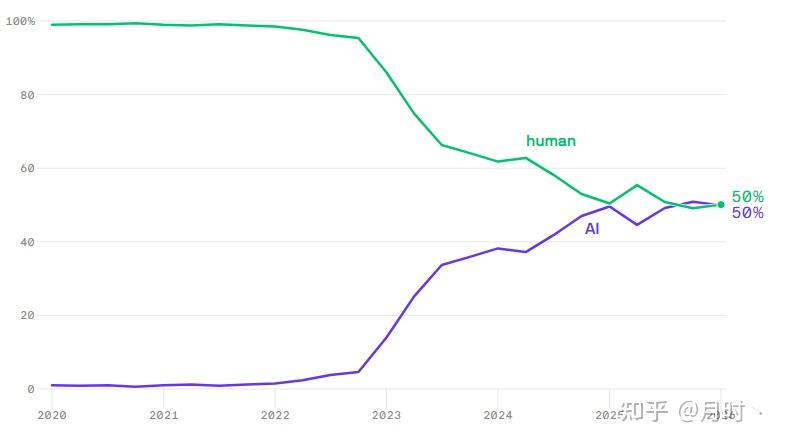
视频侧也已经出现类似问题。The Guardian 2025 年 12 月报道,Kapwing 新建 YouTube 账号测试推荐流,发现前 500 个推荐视频中有 104 个属于 AI slop,占比超过 20%。Kapwing 还调查了全球 15,000 个热门 YouTube 频道,发现其中 278 个频道完全由 AI slop 构成。

这个背景下,谷歌和 OpenAI 推出识别工具,逻辑上是对的。问题是,这套系统识别的不是“所有 AI 内容”,而是“有没有可验证的来源信号”。
SynthID 只能识别已经嵌入 SynthID 信号的内容。OpenAI 的验证工具也只能检测 OpenAI 工具生成图片中的受支持来源信号,包括 C2PA 元数据和 SynthID 水印。OpenAI 官方说明也写得很清楚:没有检测到信号,只代表工具没有找到它支持的来源信号,图片仍可能由 OpenAI 工具生成。
所以,“未检测到”不等于“不是 AI 生成的”。
这个区别,我觉得很多人会搞混。
水印能被去掉吗
这是我最想知道的问题。
SynthID 的设计目标是抗篡改——谷歌说即使图像被裁剪、压缩、编辑,水印仍然可以被检测到。 上面的实际测试也说明了这一点。Nature 那篇论文也验证了这一点,在多种攻击场景下准确率保持稳定。
但"稳定"不是"不可破"。
C2PA 元数据的情况更直接。元数据是附加在文件里的,不是嵌入像素的。截图一张图片,元数据就没了。重新保存,元数据可能就没了。用任何图像编辑软件处理一下,元数据大概率就没了。
C2PA 规范本身就承认这个问题,他们的解决方案是"软绑定"——把元数据的哈希值嵌入图像内容,这样即使元数据被剥离,也能检测到"这张图曾经有过 C2PA 证书"。但这需要检测工具支持这个功能,而且只能告诉你"证书被移除了",不能告诉你原始内容是什么。
所以这套系统的实际效果是:对于合规使用主流工具、没有刻意规避的内容,识别率不错。对于任何想绕过的人,门槛不高。
这不是在否定这套系统的价值。只是想说清楚它能做什么、不能做什么。
那这件事有没有意义
AI 生成内容占到 50% 这个数字,意味着互联网上的信息环境已经发生了结构性变化。在这个背景下,任何让内容"留下痕迹"的努力都是有价值的——哪怕这个痕迹可以被抹掉,哪怕这套体系有漏洞。
谷歌把 SynthID 开源,让更多工具可以接入,是对的。C2PA 把超过 5000 个组织拉进来建立行业标准,是对的。OpenAI 做一个公开可用的验证工具,是对的。
这些事情加在一起,会让"主动规避"的成本变高,会让"无意识传播 AI 内容"的情况减少,会让普通用户有一个可以查的工具。
但它不会解决深度伪造,不会阻止恶意使用,不会让互联网变回"可信"的状态。
我想到一个问题,一直没想清楚:
如果有一天,所有 AI 生成的内容都被完美标记了,我们会更信任互联网,还是更不信任?
因为那意味着,所有没有标记的内容,我们都会默认是人类写的。
而人类写的东西,也不一定是真的。
往期文章👇
GPT Plus升级失败?没有虚拟卡、海外信用卡怎么办?全新技术实现24小时自助直充升级GPT
AI完成任务太耗时?想要摸鱼却又怕耽误时间,于是我做了个AI任务完成提醒器
教你在国内用一个套餐同时体验到Claude Code+Codex两大AI编程助手
最后感谢大家能够看到文章的最后,如果你觉得这篇文章对你有启发或者帮助,不妨点个关注,你的支持将是我最大的动力,我们下次见!