

AI编程用了几个月,我踩过的坑和真正好用的东西
AI编程用了几个月,我踩过的坑和真正好用的东西
大家好,我是月时~
最近忙着项目,没怎么更新公众号了,想着也打算转型了,做点AI编程相关的,毕竟自己也是计算机科班出身的,老本行不能忘。
同时也慢慢分享一些我这几个月以来的使用技巧和体验,给目前正在用AI编程迷茫的人一点经验。
说实话,刚开始用AI编程工具的时候,我的感受是AI编程还不到时候,但你能想到不到一年时间我这个观点就已经被推翻了。
很多时候不是工具不好,而是用错了方法。
我以为AI编程就是"你说需求,它出代码",然后我就可以翘着腿等结果。结果发现,我说的需求越模糊,它给的代码越离谱。有一次我让它"做个用户管理系统",它给我整了一套带RBAC权限、多租户、审计日志的完整架构——我就一个内部小工具,用户不超过20个。
那一刻我意识到,AI编程这件事,门槛不在技术,在你能不能把自己想要的东西说清楚。
你以为你知道自己要什么
我在大学学的是软件工程,需求分析这门课我当年考了92分。
然后我用AI编程工具踩了同样的坑。
问题不是我不懂需求分析,是AI太快了。它不会停下来问你"你确定要这个 ...

相隔7周推出新模型,OpenAI 这次不是在发布 GPT-5.5,是在发布一种压力【附国内如何使用到GPT-5.5】
相隔7周推出新模型,OpenAI 这次不是在发布 GPT-5.5,是在发布一种压力【附国内如何使用到GPT-5.5】
昨天晚上OpenAI新模型 GPT-5.5 正式发布,距离 GPT-5.4 发布,刚好七周。
昨天还在感慨GPT-Image-2的强大,今天又来了一个新模型。
最新生图模型GPT-Image-2发布,中文无乱码!商用价值拉满!附如何体验到 GPT-Image-2 呢?
不过这迭代速度有点快了!
GPT-5.5 到底是什么
先把基本信息说清楚。
GPT-5.5,内部代号 Spud,2026 年 4 月 23 日正式发布。
这是 OpenAI 自 GPT-4.5 以来,第一个完全重新训练的基础模型。不是微调,不是 patch,是从头来过。
Greg Brockman 在发布会上说了一句话,我觉得是这次发布的核心定义:
“a new class of intelligence for real work and powering agents”
翻译过来就是:这不是一个更聪明的聊天机器人,这是一个能自己干活的 Agent。
具体能干什么?
写代码、调试、跑研究、分析 ...
最新生图模型GPT-Image-2发布,中文无乱码!商用价值拉满!附如何体验到 GPT-Image-2 呢?
最新生图模型GPT-Image-2发布,中文无乱码!商用价值拉满!附如何体验到 GPT-Image-2 呢?
就在昨晚,GPT-Image-2正式发布。
又一个"史上最强"。又一个"颠覆性升级"。又一个让你觉得上个月刚学会的东西已经过时了的发布。
说实话,我已经有点麻了。这种发布节奏,真的很累。你刚把一个工具用顺手,它就告诉你有新版本了,你之前学的那套可以扔了。
它到底发布了什么
4 月 22 日,OpenAI 推出了 ChatGPT Images 2.0,底层模型叫 gpt-image-2。
具体来说,这次升级了什么:
会"思考"了。 这是 OpenAI 第一个带 Thinking 能力的图像模型。开启 Thinking 模式之后,它不是直接生成,而是先推理——理解你要的是什么结构、什么层次、什么逻辑关系,然后再画。
能联网。 生成之前可以搜索网络获取上下文。你让它画一张关于某个最新产品的图,它会先去查这个产品长什么样,而不是凭空想象。
一次出多张。 开启 Thinking 模式后,单个 prompt 最多生成 8 张风格 ...

Claude Opus 4.7 发布了,但你们关注错重点了(附如何使用到Opus 4.7)
Claude Opus 4.7 发布了,但你们关注错重点了(附如何使用到Opus 4.7)
Anthropic 昨天发了 Opus 4.7。
我刷到的第一条评论是:“编码又提升了!”
第二条:“打败 GPT-5.4 了!”
第三条还是编码。
我理解,编码是大家最直接能感受到的东西。但我觉得这次真正值得聊的,不是编码——是视觉。
视觉这次是真的变了
Anthropic 官方对 Opus 4.7 的定位里,专门提到了"high-resolution vision"——高分辨率视觉。
这不是随便说说的。
具体数字:图像处理分辨率提升了 3 倍,最高支持长边 2,576 像素(约 3.75 MP)。
以前你发高清图给 Claude,它会自动压缩,细节丢失,表格里的小字经常读错,截图里的代码经常看不清。现在分辨率上来了,这些问题理论上都能改善。
更高的分辨率直接带动了输出质量的连锁提升:生成界面、制作幻灯片、排版文档,细节精度也全面提升。
多个第三方评测也提到视觉能力有"质的提升"——从"将就能用"变成"可以依赖&qu ...
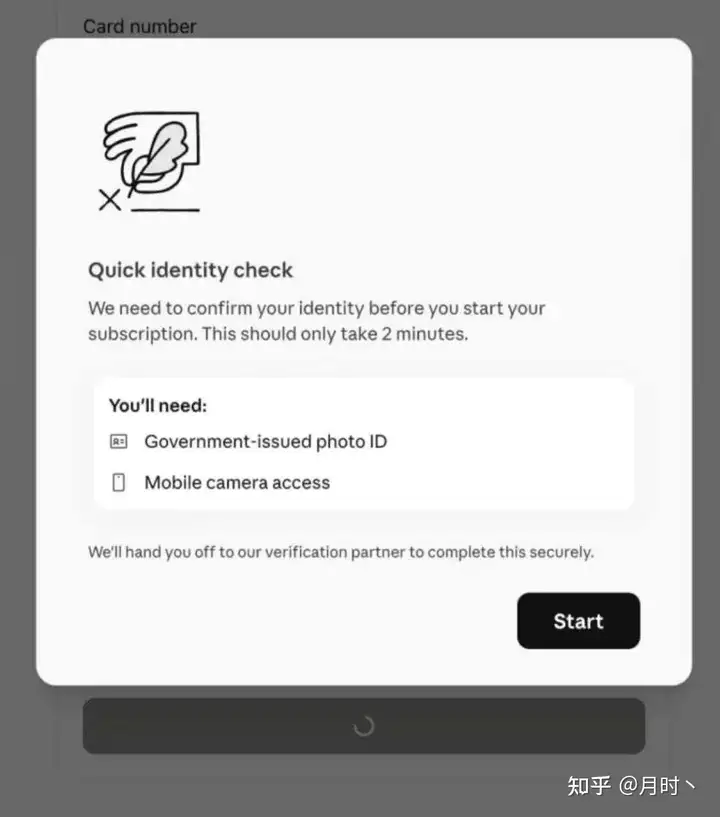
彻底玩完,Claude上实名制验证,未成年人禁止使用?
彻底玩完,Claude上实名制验证,未成年人禁止使用?
就在昨天,Claude更新了支持文档,宣布在 Claude 平台上正式引入身份验证机制
Anthropic这一轮的身份验证,其实不是一件事,是好几件事叠在一起。
第一层:年龄验证
2026年4月12日前后,大量用户反映账号被锁,系统判定他们"可能是未成年人"。当时Anthropic的官方说法是:他们要求所有用户年满18岁,如果App Store或Play Store的账号信息显示用户可能未成年,就会触发验证流程。
验证通过Yoti完成。选项有三个:上传政府颁发的ID(护照、驾照)、人脸扫描、或者其他生物特征验证。 30天内完成,否则账号永久锁定。
而现在即使你验证成功了,只要是未成年人也可能会被封禁Claude账号
通过对比调查,可以看到国外四家主流AI大厂中,目前只有Anthropic的Claude是对未成年进行限制的,即使是监护人同意也无济于事。
可以说给未成年人当头一棒了!
第二层:Persona身份验证
这个更早一些。Anthropic在部分使用场景下,启用了由Persona支持的身份验证机制— ...
一文说清ChatGPT Pro 5x 和 20x 区别,以及国内如何升级ChatGPT Pro 最新教程
一文说清ChatGPT Pro 5x 和 20x 区别,以及国内如何升级ChatGPT Pro 最新教程
之前我写过一篇文章,聊了聊
OpenAI推了个Pro $100套餐,你是否真的需要升级呢?
那篇主要是讲要不要升级的问题。
那这篇想聊得更具体一点:$100 和 $200,这两个Pro档到底差在哪,国内用户应该怎么选,又该如何升级ChatGPT Pro呢。
OpenAI现在到底有几个套餐
我整理了一下,现在个人用户一共有这几档:
Free(免费)
能用GPT-5.4,但有次数限制。美国区还加了广告。对,你没看错,免费版开始投广告了。
Go($8/月)
去年8月上线的新档。比免费版多一点用量,但只能用GPT-5.3 Instant这个基础模型,没有高级推理,也有广告。
坦率的讲,这个档位我不太理解它的定位。因此也被人们戏称"GPT阉割版"
Plus($20/月)
这是大多数人用的档位。GPT-5.3 Instant和GPT-5.4 Thinking模式都能用,有高级语音,有Deep Research(有限次数),没有广告。
Pro($100/月 和 $200/月) ...

麻了!OpenAI推出100美元的Pro套餐后,Plus的Codex额度被莫名削了?
麻了!OpenAI推出100美元的Pro套餐后,Plus的Codex额度被莫名削了?
就在昨天,OpenAI在Pro套餐中推出了100美元一档,套餐价格表正式对标Anthropic的Claude。
OpenAI推了个Pro $100套餐,你是否真的需要升级呢?
对于开发者来说,Claude Code和Codex这两个目前是最主流的AI编程助手,不过对比最近Claude模型莫名降智问题,我是毫不犹豫地转向了Codex,说明需求后Codex基本上都可以一次搞定。
不过在这两天的开发观察中,我发现在相同开发强度下,之前Plus会员的5小时额度基本用不完,但现在却很快就消耗完了,连开几个窗口,一个小时就用完了,周限制才两天也快一半了。
我不知道是不是我的错觉,还是之前的Codex促销活动结束导致的错觉~
但可以肯定的是,ChatGPT Plus 现在确实已经调整了 Codex 的用量规则,整体思路看起来越来越接近 Claude Pro。现在无论是五小时还是一周的额度窗口,基本都很容易跑满。这样一来,用户只要想稍微认真一点做编程任务,似乎就很难继续停留在 Plus,而是会被进一步引导去考虑 ...
Claude Code 新功能上线,正式开启全民赛博养宠模式!!!
Claude Code 新功能上线,正式开启全民赛博养宠模式!!!
就在前两天 Claude Code意外泄露源码,当时人们发现里面有一个虚拟宠物伙伴Buddy模式尚未发布,而现在,它来了。
什么是 Buddy 模式?
在最新版本的 Claude Codev2.1.89 中,你的编辑器旁边会出现一只可爱的小宠物,它会在你编程时陪伴你,偶尔对你的代码发表评论,甚至在你遇到困难时给出建议。它会以完整的电子宠物风格出现在你的 Claude 代码终端里,让编程过程变得更加有趣和互动。
可以通过 npm i -g @anthropic-ai/claude-code自行更新最新版本v2.1.89的
重新进入 claude 输入 /buddy 即可查看自己的宠物属性啦,每只宠物都有自己的名字
宠物的五大属性系统
每只宠物都有独特的属性值,这些属性会影响它们的行为和互动方式:
1. DEBUGGING(调试能力)
影响宠物发现代码问题的敏锐度
数值越高,越能帮你找到隐藏的 bug
提供调试建议的频率和质量也会提升
2. PATIENCE(耐心值)
决定宠物在长时间任务中的表现
高耐心值的 ...

OpenClaw + GPT-5.4,手把手教你无需购买 API 也能上手使用【附带GPT升级教程】
OpenClaw + GPT-5.4,手把手教你无需购买 API 也能上手使用【附带GPT升级教程】
就在昨天,热门智能体项目 OpenClaw 现已更新至 2026.3.7 版本,带来了上下文引擎插件、lossless-claw 等重磅功能,并进一步扩展了对一系列新模型的支持。
而本次更新中,我们可以发现其中对新模型的支持中就包含了OpenAI最新模型GPT-5.4,这个天选模型发布之后,大家也是争先恐后地想要在OpenClaw接入该模型,但奈何暂不支持授权切换。
相信很多人手中都有自己的gpt账号,现在不管是免费、Plus、Business、Pro 订阅的用户,都可以有额度去使用到ChatGPT附带的Codex。
早在二月份的时候,OpenAI首席执行官就宣布Free/Go用户目前也有 Codex 权限,只不过在额度上可能会与其他付费用户有一定的差距
如果你的GPT经常升级失败,也没有海外信用卡、虚拟卡的话,可以可以看一下往期文章👇
GPT Plus升级失败?没有虚拟卡、海外信用卡怎么办?全新技术实现24小时自助直充升级GPT
如果有其他问题的话,可以联系YueShiwa
...

GPT-5.4 深夜上线!百万上下文+原生操作电脑,OpenClaw 天选模型来了!【附GPT升级教程】
GPT-5.4 深夜上线!百万上下文+原生操作电脑,OpenClaw 天选模型来了!【附GPT升级教程】
就在今天深夜,OpenAI继GPT5.3 Instant之后又推出了一个全新模型—— GPT 5.4
OpenAI 对 GPT-5.4 的定位是:面向专业工作的最强、最高效的前沿模型,并且它已经同时上线 ChatGPT、API 和 Codex。另外还有更高规格的 GPT-5.4 Pro。
GPT-5.4 还是 OpenAI 首个把 GPT-5.3-codex 级代码能力并入主线推理模型的版本,也就是不再把“会写代码”和“懂业务/懂知识”分在两个模型上。
那么,它本次更新最核心的加强点在哪呢?我们要怎么快速升级到GPT-5.4呢?为什么说它是OpenClaw的天选模型呢?另外OpenClaw该如何切换到GPT-5.4呢?
GPT-5.4 的核心加强点
真实工作能力明显增强
这次 GPT-5.4 最核心的提升,不是单一学术跑分,而是真实专业工作任务。
GDPval(真实专业工作任务表现):GPT-5.4 为 83.0% ,GPT-5.2 为 70.9% ,提升 12.1 个百分点 ...
站长微信
若需要代充GPT Plus,购买镜像站都可以添加站长私人微信咨询哦~
微信公众号
关注微信公众号网猫科技屋,获取更多资讯
