新年难得放松一些,闲来无事,想着好久没上edu漏洞平台看看了,看看有什么礼品上架,顺便想看看朋友怎么样,但奈何平台都没有搜索功能┭┮﹏┭┮,查起来也极不方便。
于是就挤了点时间随便写了下搜索脚本,写的不多,难度不大,但功能基本包含,写得不好的地方还请大佬们多多指教。
脚本概述
本脚本主要是针对三个不同的搜索对象:用户,礼品以及高校。
信息处理上,利用Xpath和正则表达式对其进行一个对应信息的搜索获取,基本功能完整,提供可视化搜索进度。
菜单如下图👇
main函数如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 if __name__ == '__main__' : global baseUrl, headers global numStart, expectedGiftNum global red, green, yellow, blue, end red = '\033[1m\033[31m' green = '\033[1m\033[32m' yellow = '\033[1m\033[33m' blue = '\033[1m\033[34m' end = "\033[0m" headers = { 'User-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36' , 'Host' : 'src.sjtu.edu.cn' } searchFile = 'search.txt' giftFile = 'gift.txt' baseUrl = 'https://src.sjtu.edu.cn' numStart = 1 expectedGiftNum = 150 print ('\neduSrc平台脚本(小型搜索脚本) —— by Ztop' ) while True : print ('\033[1m\033[35m------------功能描述---------------\n' '1.根据用户名搜索用户信息(精确、模糊)\n' '2.搜索平台未下架礼品\n' '3.搜索指定区域内高校信息\n' '-----------------------------------\033[0m' ) choice = int (input (">>" )) if choice == 1 : print ('精确查找1 | 模糊查找2' ) fchoice = int (input ('>>' )) if fchoice > 0 and fchoice < 3 : numEnd = get_numEnd(choice) if fchoice == 1 : Exact_search(numEnd) else : Fuzzy_search(searchFile, numEnd) else : print ("%s未知选项!%s\n" % (yellow, end)) elif choice == 2 : gift_search(giftFile) elif choice == 3 : collegeFind(choice) else : print ("%s请重新输入%s\n" % (red, end))
针对用户
根据用户名搜索用户信息,考虑到使用者对用户名可能的一些情况,特意区分了精确查询和模糊查询。
精确查询
遍历Xpath获取到的数据,可视化进度条,查询到即停止,并显示在控制台,不会继续搜索。
效果图如下👇(太菜了,师傅们轻点喷)
具体代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 def Exact_search (numEnd ): while True : name = input ("%s【精确查询】%s >> 将查找的用户名:" %(yellow, end)) if name != "" : break url = baseUrl + '/user/sum/?page=' print ("%s将查询页数总共:%s %s" % (blue, numEnd, end)) time.sleep(0.5 ) flag = False for i in tqdm(range (numStart, numEnd + 1 )): Surl = url + str (i) res = requests.get(url=Surl, headers=headers) data_html = etree.HTML(res.text) name_list = data_html.xpath('//div[@id="show_list"]/table/tr[@class="row"]/td[2]/a/text()' ) level_list = data_html.xpath('//*[@id="show_list"]/table/tr[@class="row"]/td[3]/span/text()' ) rank_list = data_html.xpath('//*[@id="show_list"]/table/tr[@class="row"]/td[1]/text()' ) for j in range (len (name_list)): list_name = str (name_list[j]).strip() if name == list_name: print ("\n%s【+】目标在第 %s 页:%s\t称号:%s\t排名:%s%s\n" % (green, i, name_list[j], level_list[j], rank_list[j], end)) flag = True break if flag: break
模糊查询
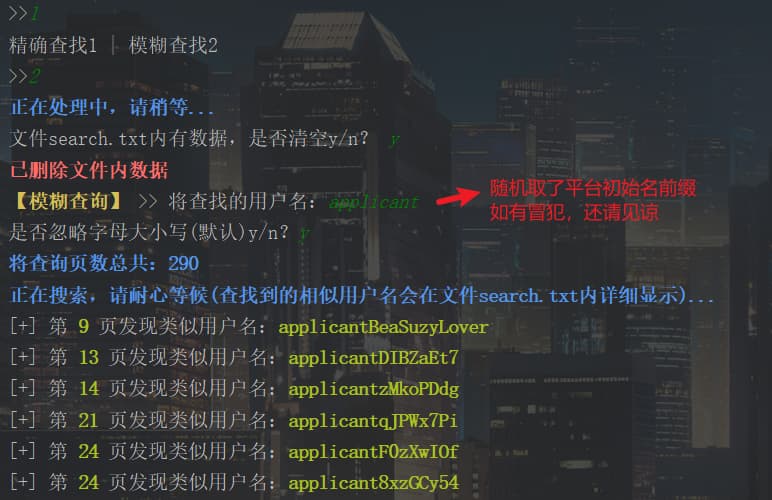
考虑到使用者对用户名可能出现的一些情况:健忘、碎片记忆、找茬等等(bushi),特别设置了模糊查询(主要是回顾正则的学习嘻嘻)
模糊查询对于使用者输入字符可以进行判断校验,需要满足的条件有:
自动匹配不完整字符输入
可选择忽略字母大小写
利用了正则表达式对其进行一个判断筛选,将使用者输入的字符融入到正则表达式中,再对获取到的数据进行匹配。
这里获取到的数据是通过Xpath提取出来的列表,可通过for循环遍历列表元素逐一进行匹配筛选。
搜索到的模糊用户名会储存在自定义文件search.txt中,并显示详细信息,遍历用户不会中途停止,搜索完成后会显示具体的数据统计结果。
1 2 3 4 5 6 7 8 name = input ("用户名:" ) result = re.match('(.*)' + name + '(.*)' , 获取的数据) pattern = re.compile (r'(.*)' + name + '(.*)' , re.I) result = pattern.search( 获取的数据 )
效果图如下👇
具体自定义函数代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 def Fuzzy_search (file, numEnd ): is_empty(file) try : while True : name = input ("%s【模糊查询】%s >> 将查找的用户名:" %(yellow, end)) if name != "" : break except : pass is_ignoreCase = input ('是否忽略字母大小写(默认)y/n?' ).lower() url = baseUrl + '/user/sum/?page=' print ("%s将查询页数总共:%s \n" "正在搜索,请耐心等候(查找到的相似用户名会在文件%s内详细显示)...%s" % (blue, numEnd, file, end)) userNum = 0 count = 0 for i in range (numStart, numEnd + 1 ): Surl = url + str (i) res_data = requests.get(url=Surl, headers=headers) data_html = etree.HTML(res_data.text) name_list = data_html.xpath('//div[@id="show_list"]/table/tr[@class="row"]/td[2]/a/text()' ) level_list = data_html.xpath('//*[@id="show_list"]/table/tr[@class="row"]/td[3]/span/text()' ) rank_list = data_html.xpath('//*[@id="show_list"]/table/tr[@class="row"]/td[1]/text()' ) rankNum = 0 for j in name_list: if is_ignoreCase == "n" : result = re.match('(.*)' + name + '(.*)' , str (j)) else : pattern = re.compile (r'(.*)' + name + '(.*)' , re.I) result = pattern.search(str (j)) if result: count += 1 findName = result.group() print ("[+] 第 %s%s%s 页发现类似用户名:%s%s%s" % (green, i, end, green, findName, end)) with open (file, 'a' , encoding="utf-8" ) as f: f.write("第 %s 页:\t%s \t称号:%s\t排名:%s\n" % (i, findName, level_list[rankNum], rank_list[rankNum])) rankNum += 1 userNum += 1 if count != 0 : print ("\n%s查找用户人数共 %s,总计发现了%s个相似用户名%s\n" % (green, userNum, count, end)) else : print ("\n%s很遗憾,未找到相似用户名%s\n" % (red, end))
针对礼品
平台某个礼品在没有库存时,并不会进行下架操作,但会在客户端中隐藏起来,可通过url查找。
我们可以通过脚本搜索到所有礼品,包括没有库存的,并进行一个区分统计。
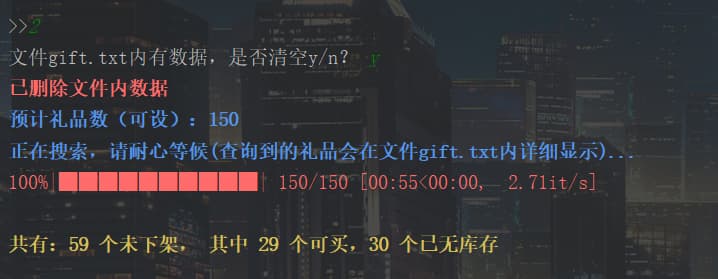
因为不知道礼品具体有多少个,为了方便设置,就在main函数中,把参数设为全局变量expectedGiftNum,这里可自设一个数进行遍历(据说150可以遍历到所有)
查询到的礼品详细信息会保存在自定义文件gift.txt中。
效果图如下👇
具体代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def gift_search (file ): is_empty(file) url = baseUrl + '/gift/' count = 0 buyNum = 0 print ("%s预计礼品数(可设):%s \n" "正在搜索,请耐心等候(查询到的礼品会在文件%s内详细显示)...%s" % (blue, expectedGiftNum, file, end)) for i in tqdm(range (expectedGiftNum)): gift_url = url + str (i) res = requests.get(url=gift_url, headers=headers) html = etree.HTML(res.text) if "Not Found" not in res.text: giftName = html.xpath('/html/body/div/div/div[1]/div/div/div[1]/div[2]/text()' )[0 ].strip() num = html.xpath('/html/body/div/div/div[1]/div/div/div[3]/div[2]/span/strong/text()' )[0 ].strip() coins = html.xpath('/html/body/div/div/div[1]/div/div/div[2]/div[2]/text()' )[0 ].strip() if int (num) != 0 : buyNum += 1 with open (giftFile, 'a' , encoding="utf-8" ) as f: f.write(gift_url + "\t\t库存" + num + "\t\t" + coins + "\t\t" + giftName + "\n" ) count += 1 print ("\n%s共有:%s 个未下架, 其中 %s 个可买,%s 个已无库存%s\n" % (yellow, count, buyNum, count - buyNum, end))
针对高校
本来的想法是想弄这个模式的二级菜单:全国内、各省份,但发现两个代码有点类似,感觉全国内那个单独分开有点冗余,于是就把它们合在一个查找中。
效果图如下👇
具体代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 def collegeFind (choice ): url = baseUrl + '/rank/firm/' print ('%s正在获取各区域/省份信息....%s' %(blue, end)) res = requests.get(url=url, headers=headers) data_html = etree.HTML(res.text) provinceList = data_html.xpath('//*[@id="id_province"]/option/text()' ) for i in range (len (provinceList)): print (f'{i} . {provinceList[i]} ' , end="\t" *4 ) if (i+1 )%6 == 0 or i == len (provinceList)-1 : print ('' ) try : while True : province_id = int (input ('请输入高校所在区域/省份对应编号:' )) if province_id < 0 or province_id >= len (provinceList): print ('%s输入超出限制!%s' %(red, end)) else : break except : pass print ("\n%s【%s】 >>%s 将查找的高校名:" %(green, provinceList[province_id], end), end="" ) college_name = input ('' ) numEnd = get_numEnd(choice, province_id) for i in tqdm(range (numStart, numEnd+1 )): search_url = url + '?province=%s&page=%s' % (province_id, i) try : flag = False ress = requests.get(url=search_url, headers=headers) data_html = etree.HTML(ress.text) schoolNameList = data_html.xpath('/html/body/div/div/div[1]/div/div/table/tr[*]/td[2]/a/text()' ) bugNumList = data_html.xpath('/html/body/div/div/div[1]/div/div/table/tr[@class="row"]/td[3]/text()' ) bugThreatList = data_html.xpath('/html/body/div/div/div[1]/div/div/table/tr[@class="row"]/td[4]/text()' ) for j in range (len (schoolNameList)): schoolName = schoolNameList[j].strip() if schoolName == college_name: print ('%s【+】目标【%s】在【%s】列表中第 %s 页, 第 %s 个,id为%s,漏洞总数为%s,漏洞威胁值为%s%s\n' % (green, college_name, provinceList[province_id], i, j+1 , (i-1 )*15 +(j+1 ), bugNumList[j], bugThreatList[j], end)) flag = True break if flag: break except : pass if flag != True : print ('%s【*】查询不到该高校信息,可能是高校名错误或暂未收录%s\n' % (red, end))
最后
这个脚本是一时兴起写的,很多情况可能没有考虑到,但总体效果达到我的预期了。线程提高速度。