
Scrapy爬虫框架
Scrapy框架概念
Scrapy是一个Python编写的开源网络爬虫框架。它是一个被设计用于爬取网络数据、提取结构性数据的框架。
Scrapy文档地址:http://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/overview.html
Scrapy框架作用
少量的代码,就能够快速的抓取。一般用于爬取大量数据。
Scrapy框架工作流程
-
回顾request的爬虫流程
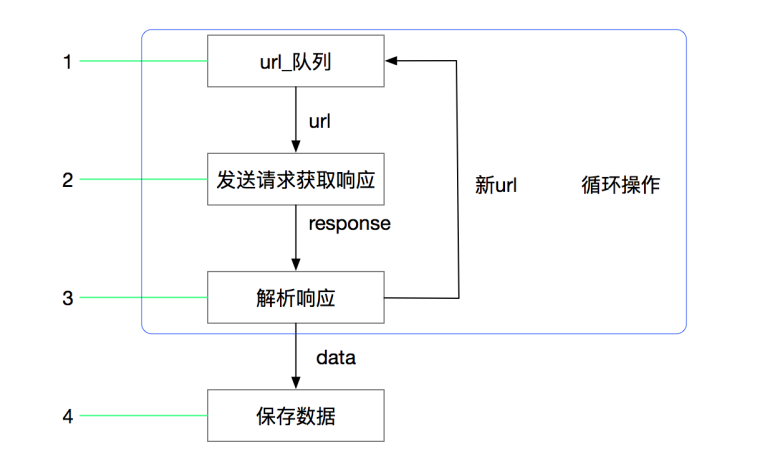
我们可以在此基础上改写流程:
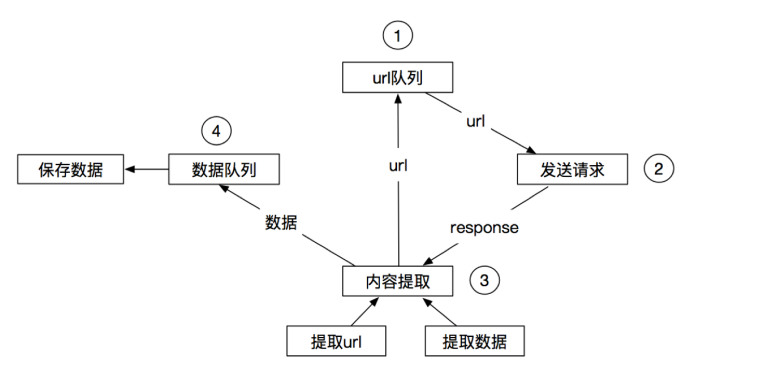
而上面改写的流程图也更加便于大家去理解scrapy的流程
-
Scapy的流程
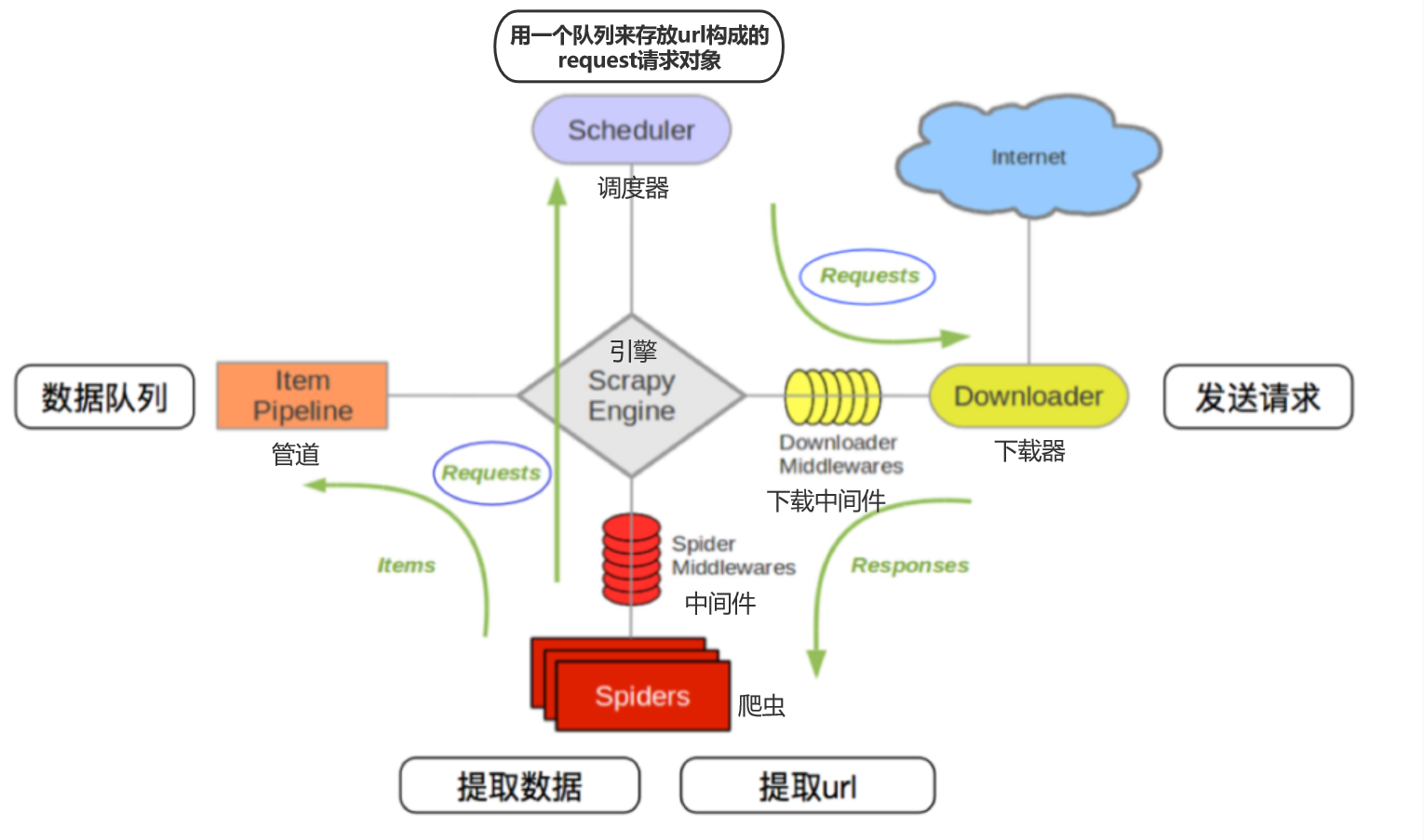
其流程详细如下:
- 爬虫中起始的url构造成request对象——>爬虫中间件——>引擎——>调度器
- 调度器把request——>引擎——>下载中间件——>下载器
- 下载器发送请求,获取response响应——>下载中间件——>引擎——>爬虫中间件——>爬虫
- 爬虫提取url地址,组装成request对象——>爬虫中间件——>引擎——>调度器,重复步骤2
- 爬虫提取数据——>引擎——>管道处理和保存数据
各模块的具体作用

各模块功能:
- 引擎 —— 数据和信号的传递
- 调度器 —— 任务url队列
- 下载器 —— 发送请求、获取响应
- 爬虫 —— 起始的url、解析数据
- 管道 —— 保存数据
- 中间件 —— 定制化操作
三个内置对象
- request请求对象:由url、method、post_data、headers等构成
- response响应对象:由url、body、status、headers等构成
- item数据对象:本质是个字典
安装
有时pip版本过于老旧不能使用,需要升级pip版本,输入pip install --upgrade pip回车,升级成功
安装scrapy命令:
1 | pip/pip3 install Scrapy |
scrapy项目开发流程
- 创建项目
- 生成一个爬虫
- 提取数据
- 保存数据
创建项目
创建scrpy项目的命令:
1 | scrapy startproject <项目名字> |
示例:
1 | scrapy startproject myspider |
创建爬虫
通过命令创建出爬虫文件,爬虫文件为主要的代码作业文件,通常一个网站的爬取动作都会在爬虫文件中进行编写。
命令:在项目路径下执行
1 | scrapy genspider <爬虫名字> <允许爬取的域名> |
- 爬虫名字:作为爬虫运行时的参数
- 允许爬取的域名:为对于爬虫设置的爬取范围,设置之后用于过滤要爬取的url,如果爬取的url与允许的域不通则被过滤掉。如不确定时,可以设置xx.com,后期再进行修改。
这里我们以豆瓣电影Top250作为示例:
1 | cd myspider |
生成的目录和文件结果如下:

完善爬虫
在上一步生成出来的爬虫文件中编写指定网站的数据采集操作,实现数据提取
一、在item.py中定义要提取的字段
1 | import scrapy |
二、在/myspider/myspider/spiders/douban.py 中修改内容如下
1 | import scrapy |
三、定位元素以及提取数据、属性值的方法
解析并获取scrapy爬虫中的数据: 利用xpath规则字符串进行定位和提取
-
response.xpath方法的返回结果是一个类似list的类型,其中包含的是selector对象,操作和列表一样,但是有 一些额外的方法
-
额外方法extract():返回一个包含有字符串的列表(相当于getall() )
-
额外方法extract_first():返回列表中的第一个字符串,列表为空没有返回None(相当于get() )
四、response响应对象的常用属性
- response.url:当前响应的url地址
- response.request.url:当前响应对应的请求的url地址
- response.headers:响应头
- response.requests.headers:当前响应的请求头
- response.body:响应体,也就是html代码,byte类型
- response.status:响应状态码
五、(改进版)可构造Request对象,并发送请求
1 | import scrapy |
scrapy.Request()中的常见参数解释
| 参数 | 解释 | 是否必填 |
|---|---|---|
| url | 请求的url | 是 |
| callback | 回调函数,用于接收请求后的返回信息,若没指定,则默认为parse()函数 | 是 |
| meta | 方法之间以字典形式传递参数,这个参数一般也可在middlewares中处理 |
否 |
| method | http请求的方式,默认为GET请求,一般不需要指定。若需要POST请求,建议使用用scrapy.FormRequest() |
否 |
| headers | dict类型,请求头信息,一般在settings中设置即可,也可在middlewares中设置 | 否 |
| cookies | dict或list类型,请求的cookie | 否 |
| dont_filter | 是否开启过滤,默认关闭,开启之后爬取过的url,下一次不会再爬取 | 否 |
| errback | 抛出错误的回调函数并打印出来,错误包括404,超时,DNS错误等 | 否 |
保存数据
利用管道pipeline来处理(保存)数据
一、在pipelines.py文件中定义对数据的操作
- 定义一个管道类
- 重写管道类的process_item方法
- process_item方法处理完item之后必须返回给引擎
- 定义数据的保存逻辑
1 | import json |
- def open_spider(self, spider) —— 爬虫
开启时执行一次,可用来打开文件 - def process_item(self, item, spider) ——实现数据的写入操作
- def close_spider(self, spider) —— 爬虫
关闭时执行一次,可用来关闭文件
二、在settings.py 配置启用管道
1 | # 启用管道配置 |
setting.py一般都会将管道配置注释掉,取消注释即可。
配置项中键为使用的管道类,管道类使用.进行分割,第一个为项目目录,第二个为文件,第三个为定义的管道类。 配置项中值为管道的使用顺序,设置的数值越小越优先执行,该值一般设置为1000以内。
运行爬虫
命令:在项目目录下执行
1 | scrapy crawl <爬虫名字> (--nolog) |
—nolog:不显示调试信息,不加即默认显示
示例:
1 | scrapy crawl douban --nolog |
运行结果如下:
crawlspider爬虫
回顾之前的代码,有很多一部分时间都寻找下一页的url地址或者内容的url地址上面,而这个过程能更简单吗?
需求思路:
- 从response中提取所有的满足规则的url地址
- 自动的构造自己requests请求,发送给引擎
而crawlspider就可以满足上述需求,能够匹配满足条件的url地址,组装成Reuqest对象后自动发送给引擎, 同时能够指定callback函数,
即:crawlspider爬虫可以按照规则自动获取连接
创建crawlspider爬虫并观察爬虫内的默认内容
一、创建crawlspider爬虫:
1 | scrapy genspider -t crawl douban movie.douban.com |
二、spider中默认生成的内容如下:
1 | import scrapy |
三、观察其与跟普通的scrapy.spider的区别
在crawlspider爬虫中,没有parse函数
重点在rules中:
- rules是一个元组或者是列表,包含的是Rule对象
- Rule表示规则,其中包含LinkExtractor,callback和follow等参数
- LinkExtractor:连接提取器,可以通过
正则或者是xpath来进行url地址的匹配 - callback :表示经过连接提取器提取出来的url地址响应的回调函数,可以没有,没有表示响应不会进行回调函数 的处理
- follow:连接提取器提取的url地址对应的响应是否还会继续被rules中的规则进行提取,True表示会,Flase表示不会
四、crawlspider使用的注意点
- 除了用命令
scrapy genspider -t crawl <爬虫名> <allowed_domail>创建一个crawlspider的模板,页可以手动创建 - crawlspider中
不能再有以parse为名的数据提取方法,该方法被crawlspider用来实现基础url提取等功能 - Rule对象中LinkExtractor为固定参数,其他callback、follow为可选参数
- 不指定callback且follow为True的情况下,满足rules中规则的url还会被继续提取和请求
- 如果一个被提取的url满足多个Rule,那么会从rules中选择一个满足匹配条件的Rule执行
五、crawlspider其他知识点的了解
- 链接提取器
LinkExtractor的更多常见参数- allow:满足括号中的’re’表达式的url会被提取,如果为空,则全部匹配
- deny:满足括号中的’re’表达式的url不会被提取,优先级高于allow
- allow_domains:会被提取的链接的domains(url范围),如: [‘hr.tencent.com’, ‘baidu.com’]
- deny_domains:不会被提取的链接的domains(url范围)
- restrict_xpaths:使用xpath规则进行匹配,和allow共同过滤url,即xpath满足的范围内的url地址会被 提取,如: restrict_xpaths=‘//div[@class=“pagenav”]’
Rule常见参数- LinkExtractor:链接提取器,可以通过正则或者是xpath来进行url地址的匹配
- callback:表示经过连接提取器提取出来的url地址响应的回调函数,可以没有,没有表示响应不会进行回调 函数的处理
- follow:连接提取器提取的url地址对应的响应是否还会继续被rules中的规则进行提取,默认True表示会, Flase表示不会
- process_links:当链接提取器LinkExtractor获取到链接列表的时候调用该参数指定的方法,这个自定义方 法可以用来过滤url,且这个方法执行后才会执行callback指定的方法



