Anthropic 说 Opus 4.8 来了,额度刷新了,但我一直在想那个没开放的 Mythos
Anthropic 说 Opus 4.8 来了,额度刷新了,但我一直在想那个没开放的 Mythos
Anthropic 凌晨发布 Opus 4.8。
很多人第一反应不是去看发布公告,而是发现 —— Claude 的额度重置了。
这周额度早就见底的人,4.8 一来直接原地复活。
我理解这个感受。但我看完发布公告,脑子里一直转的是另一件事。
是 Mythos。
先说 Opus 4.8
先把 Opus 4.8 说清楚。
Anthropic 自己的定性是"modest but tangible improvement"——适度但可感知的提升。这个措辞我觉得挺诚实的,没有过度吹。
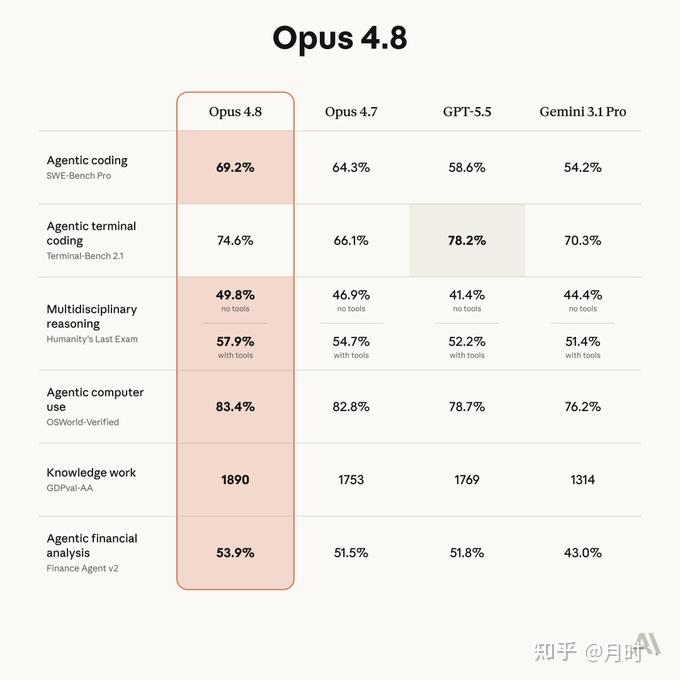
1. 代码能力真第一吗?
SWE-Bench Pro(agentic coding 基准):Opus 4.8 拿到 69.2% ,Opus 4.7 是 64.3%,GPT-5.5 是 58.6%,Gemini 3.1 Pro 是 54.2%。差距不小,代码这块是 Anthropic 现在最硬的护城河。
但有一个地方输了:Terminal-Bench 2.1,也就是终端编程任务,GPT-5.5 是 78.2%,Opus 4.8 是 74.6%。差距不大,但确实输了。如果你主要用终端操作,GPT-5.5 在这块还有一战之力。
不过仔细看的话,根据官方给的注释,GPT-5.5的实际得分应该是远大于Opus 4.8,只不过是为了拉低他的评分,从而让他到一个新的考场。

而且现在也很少人用网页去写代码了吧,基本上都是终端这些来搞定的,所以嗯~还是等5.0吧,应该会一个更大提升。
2. 诚实这件事,比 benchmark 更重要
这次 Anthropic 重点强调了一个不太容易量化的改进:Opus 4.8 更诚实了。
具体说:它在自己写的代码里,让错误"悄悄过去"的情况减少了 4 倍。更愿意承认不确定性,更少为了凑个答案而硬编,对自己干到哪一步也能做出更真实的判断。
这件事的重要性,得换个角度说才说得清楚。
AI 写出有 bug 的代码,这不是新鲜事。真正的危险是:它没有验证、没有把握,却用一种稳健自信的语气告诉你"这段代码没问题"——仿佛一切都完美运行过一遍。你信了,上线了,然后出事了。
所以 Opus 4.8 的改变,不是"它写的代码更少出错了",而是"它更清楚自己什么时候不确定了"。这两件事差别很大。
幻觉率方面,第三方评测机构 Artificial Analysis的数据是 35.9%,和 Opus 4.7 基本持平。这个数字不算好看,但也没有变差。
3. 新增Dynamic Workflows
这次跟 Opus 4.8 一起放出来的,是 Claude Code 的新功能 Dynamic Workflows,目前是研究预览。
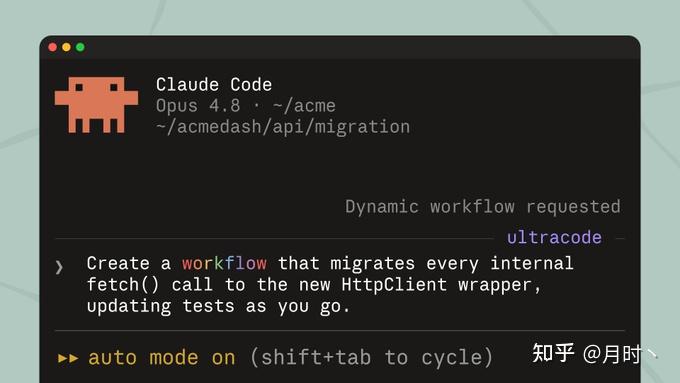
你给它一个大任务,它自己拆解,一次性派出几十到几百个并行 subagent 去干。干完之后,会让另一批 agent 去验证——甚至专门派 agent 去挑刺、反驳,反复迭代到结果收敛,最后给你一个整合好的答案。整个过程能跑几小时甚至几天,中途断了还能接着跑。
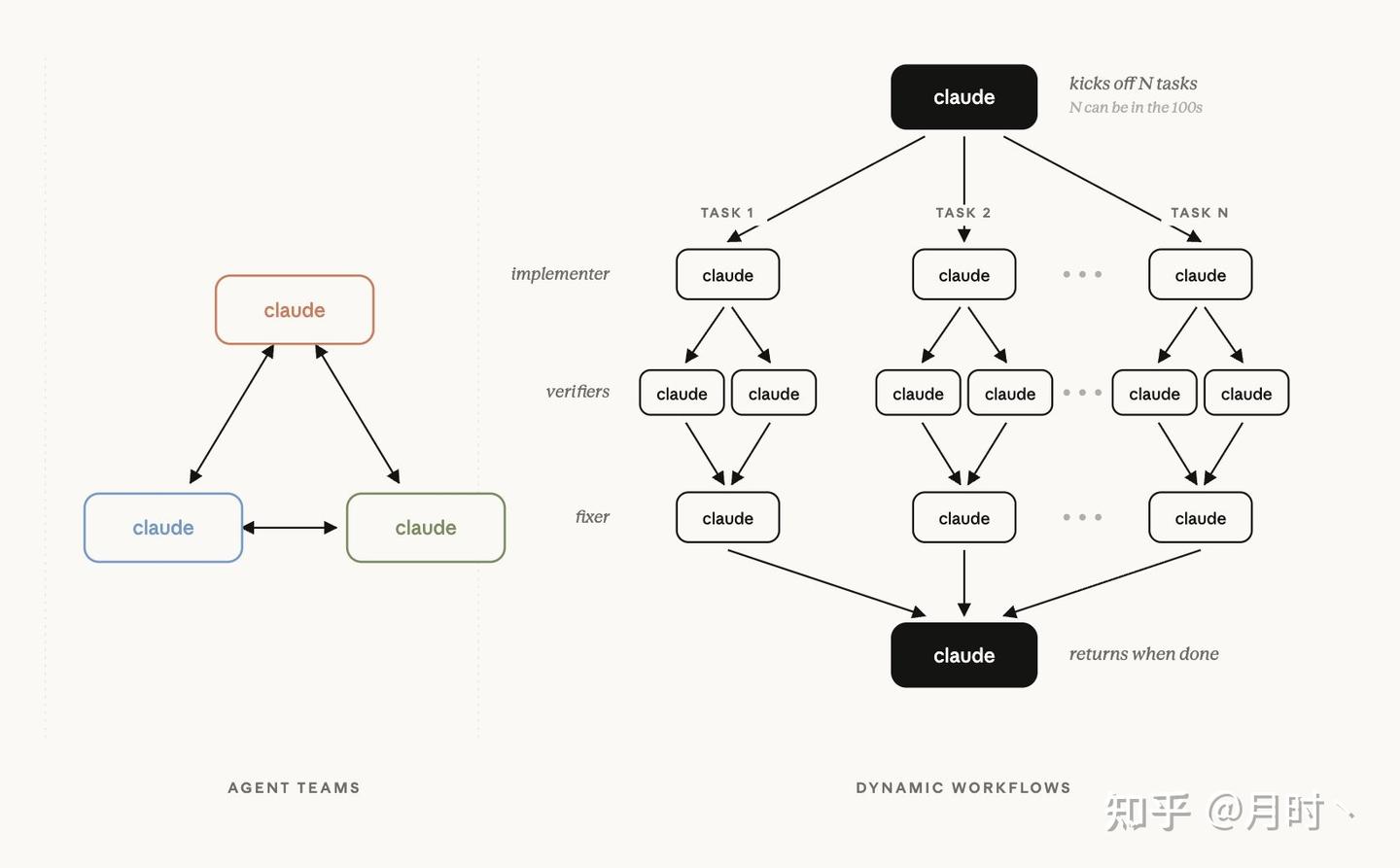
Anthropic 拿 Bun 的案例做宣传:创始人 Jarred Sumner 用 Dynamic Workflows 把整个项目从 Zig 移植到 Rust,写了约 75 万行 Rust 代码,通过了 99.8% 的原有测试,从第一次提交到合并只花了 11 天。
适合的场景:整个代码仓库的 bug 排查、安全审计、大规模迁移(框架升级、API 替换、跨语言移植,一次涉及上千个文件那种)。
但 Anthropic 罕见地主动警告:这个功能很烧 token,建议先拿小任务试水。第一次触发时,Claude Code 会先把要跑的东西摆给你看、让你确认。
目前 Max、Team 套餐和 API 用户默认开启,Enterprise 默认关闭。开启方式:直接让 Claude “建个 workflow”,或者打开 ultracode 开关(
/effort ultracode)。
4. Effort Controls:你来决定它用多少脑子
这次还有一个容易被忽略的功能:Effort Controls。
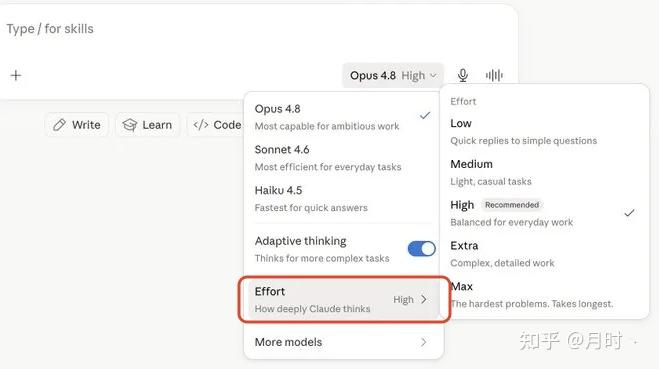
用户现在可以控制 Claude 在一个任务上投入多少"努力",从 Low 到 Max 可调。逻辑很直接——不是所有任务都需要最高智力。你问一个简单问题,没必要让模型深度思考 30 秒;你做一个复杂的代码审查,才需要它全力以赴。以前这个是模型自己决定的,现在交给你控制。
5. Fast Mode:速度快了,但 API 用户要排队
Fast Mode 现在跑到 2.5 倍速度,价格是原来的三分之一。在 Claude Code 里用 /fast 打开就行。
但 API 用户有个坑:Fast Mode 目前需要联系客户经理申请,或者排队等待,不是直接开放的。
标准版价格没涨,还是 $5 / $25 per million tokens,和 Opus 4.7 一样。
6. 效率这块有个有意思的数据
Opus 4.8 完成同样任务,比 Opus 4.7 少用 15% 的 turns,少输出 35% 的 tokens。
但有一个对比数字值得注意:Opus 4.8 完成任务还是比 GPT-5.5 多用大约 30% 的 turns。也就是说,Opus 4.8 在代码质量上赢了 GPT-5.5,但在"用多少步完成任务"这件事上,GPT-5.5 更高效。如果你的场景对 API 调用次数敏感,这个差距是真实存在的。
现在说 Mythos
Mythos 是 4 月 7 号宣布的,比 Opus 4.8 早了将近两个月。
Anthropic 没有走正常的产品发布流程,而是在安全研究子域名上发了公告,同时宣布了一个叫 Project Glasswing 的计划:Mythos 不对公众开放,只给约 50 家经过审查的机构使用——Amazon、Apple、Microsoft、Google、JPMorgan 这些。
为什么不开放?因为它太擅长找漏洞了。
SWE-bench Verified 93.9%,Cybench 满分,CyberGym 83.1%。拿 Firefox 的 JS 引擎漏洞测试,Mythos 生成可用攻击代码的成功率是 84%,Opus 4.6 是 15.2%。同一家公司的两个模型,差了将近 6 倍。
Project Glasswing 运行一个月,找到了超过 10,000 个高危或严重级别的漏洞。发现的漏洞按惯例保密 90 天——也就是说,现在已经有一批漏洞被找到了,但你还不知道是什么。
关于什么时候对公众开放,Anthropic 的回答是:也许 12 个月后。然后他们补了一句:包括我们自己在内,目前没有任何公司建立了足够强的防护措施。

这句话是 Anthropic 自己说的。
而 Anthropic 也将在未来几周内向公众发布 Mythos 这一事实,之后可能会削弱掉这部分的漏洞攻击功能。

最后有话说
所以 Opus 4.8 是什么?
我觉得它是 Anthropic 公开产品线上一次扎实的迭代。代码更强,更诚实,Fast Mode 更快更便宜,Dynamic Workflows 给大型工程任务开了一扇新门。如果没有 Mythos,这会是一次很好的发布。
但有了 Mythos 这个背景,Opus 4.8 看起来更像是——Anthropic 在公开产品线上能给你的东西,而他们真正在做的那个更激进的东西,还在另一条线上跑着。
额度刷新了,这是真的。
Mythos 还没开放,这也是真的。
往期文章👇
GPT Plus升级失败?没有虚拟卡、海外信用卡怎么办?全新技术实现24小时自助直充升级GPT
AI完成任务太耗时?想要摸鱼却又怕耽误时间,于是我做了个AI任务完成提醒器
教你在国内用一个套餐同时体验到Claude Code+Codex两大AI编程助手
最后感谢大家能够看到文章的最后,如果你觉得这篇文章对你有启发或者帮助,不妨点个关注,你的支持将是我最大的动力,我们下次见!